
On compte 140 CSX sur la région Pays de la Loire. Tous ont des modes de fonctionnements, des activités et des populations qui leurs sont propres. Il est bien évident que dans la durée de notre étude on ne peut prétendre à la réalisation d’une analyse exhaustive de chacune de ces structures.
C’est pourquoi nous avons voulu réaliser une typologie de centres sociaux, afin de les classer en grandes catégories. A partir d’un nombre limité de structures enquêtées nous pourrons en tirer des enseignements généralisables à l’ensemble.
Pour construire cette typologie, nous avons recours à une analyse multivariée. Ce type d’analyse permet de prendre en compte plus de 2 variables à la fois, afin d’apporter plus d’éléments à notre typologie qu’une combinaison entre mode de gestion associative/collectivité locale et territoire quartier/commune. On pourra ainsi prendre en compte des facteurs comme les actions « bien-vieillir » ou les instances de gouvernance.
Parmi les différentes méthodes d’analyse multivariée, on utilise ici une analyse en correspondance multiple (ACM), puisqu’elle permet de traiter des variables qualitatives (territoire : quartier, commune, etc.) et quantitatives (nombre de bénévoles, etc.). L’ACM permet de déterminer des proximités entre des modalités de variables différentes ou entre individus pour en tirer des enseignements. Ainsi des grands profils de centres sociaux peuvent émerger à partir de divers critères observés.
Dans une population aussi variée que celle des CSX, une telle méthodologie a pour but de se défaire des particularités de l’individu (un cs) afin de comprendre les dynamiques majeures de notre population (les CSX pays de la Loire). L’enjeu est donc de produire un panel de centres sociaux représentatifs par leurs actions et/ou par les caractéristiques de leur territoire.
Notre analyse présente deux volets, dissociant les caractéristiques territoriales des caractéristiques des centres sociaux. Cela devrait permettre d’extraire les centres sociaux de leur contexte territorial et de ne considérer dans un premier temps que leurs caractéristiques structurales. La définition d’un centre social montre bien que l’inscription dans un territoire est cruciale. Néanmoins, il nous semble important de procéder dans un premier temps à cette “déterritorialisation” de façon à obtenir les caractéristiques des structures qui nous intéressent. Pour conserver l’intégralité des spécificités de chaque centre, la dimension territoriale est analysée de son côté. L’objectif ici est bien de construire une analyse simultanée des différentes variables qui caractérisent les CSX et leurs territoires d’implantation.
Précisons que dans la typologie sont pris en compte la totalité des centres sociaux des pays de la Loire, qu’ils soient fédérés ou non.
Construire et comprendre les nouvelles variables de centre.
Nous avons élaboré une base de données constituée d’informations provenant de SENACS (système d’échanges National des centres sociaux). Cet outil permet d’obtenir un inventaire de la totalité des structures reconnues comme centre social. Cette analyse repose donc sur le résultat de l’enquête menée auprès des CSX-Pays de la Loire en 2014, première année de l’intégration de la région dans le périmètre de l’enquête (Par conséquent, nous ne pouvons pas faire de comparaisons temporelles).
Choisir les variables :
A partir de ces informations nous avons retenu 8 critères principaux à retenir dans notre ACM.
- Mode de gestion: La gestion d’un centre social peut-être de plusieurs types et caractérise en parti son mode de fonctionnement.
- Nombre de collectivités territoriales qui donnent une aide: Au vu de la dimension territoriale du projet et de ses retombées espérées, cette information semble essentielle. L’implication d’une ou de plusieurs collectivités dans l’activité d’un centre est éloquente.
- Nombre salariés & Heures bénévoles: Un centre social fonctionne grâce au travail collaboratif de salariés et de bénévoles. Cette caractéristique est au cœur même de sa définition. Ainsi, connaître la part des moyens humains dont dispose les structures analysées est un indicateur de leur dynamique.
- Instances de gouvernances et implication des habitants: Mesurer la place qui est accordée aux habitants dans les instances de gouvernance et de participation du centre, permet de saisir ces enjeux et d’observer d’éventuels écarts en fonction des structures.
- Actions Bien vieillir: A travers cette question, il est possible d’observer les centres qui se disent agir sur le vieillissement et ceux qui au contraire n’identifient aucune action.
- Partenariat Bien vieillir: Celles-ci renseignent sur les structures qui ont entrepris des démarches avec des instances expertes, signe d’un intérêt pour la question.
- Taille du territoire: Tout comme son mode de gestion, le territoire d’intervention est un indicateur du fonctionnement de la structure.
Si l’ACM permet effectivement de traiter simultanément des variables qualitatives et quantitatives, ce n’est possible qu’à partir du moment où elles sont converties en catégories. Or, les critères descriptifs retenus pour les CSX dans la base de données SENACS présentent des variables qualitatives et quantitatives à transformer en catégorielles. L’ensemble des étapes de recodage et de traitement et le détail de nouvelles variables et modalités de celles-ci sont reprise dans le tableau 1.
Tableau 1
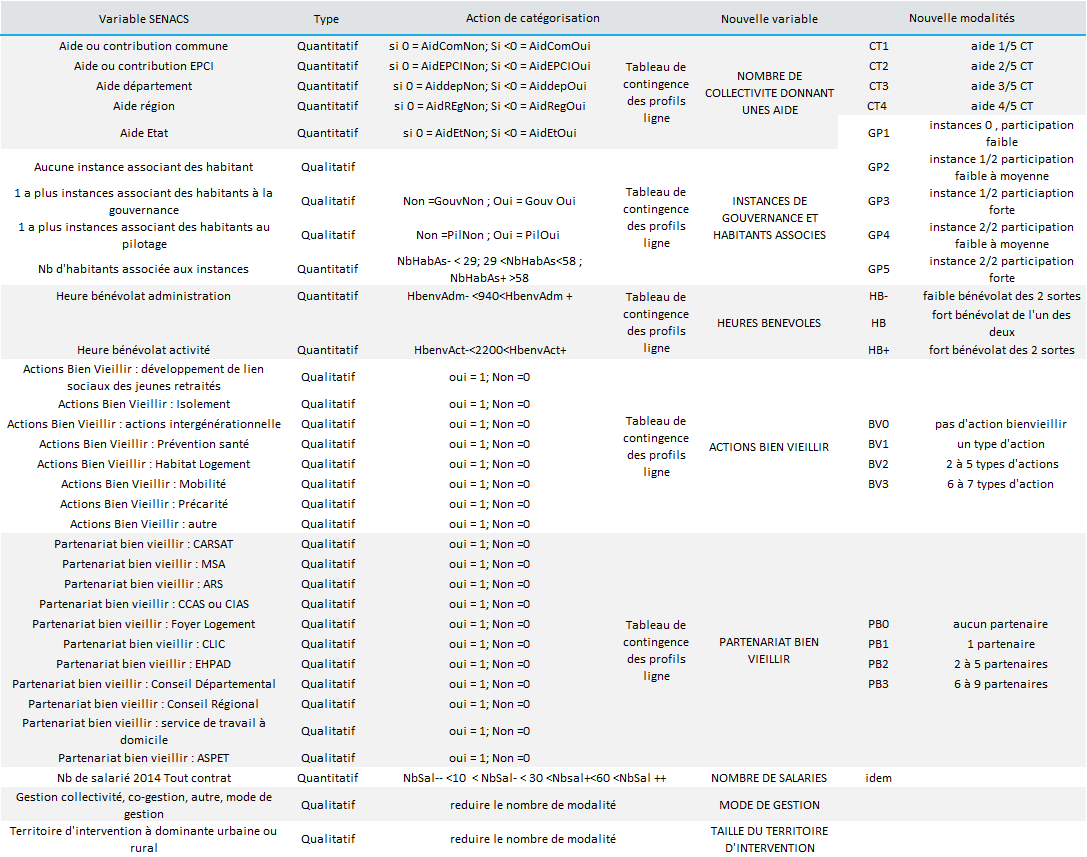
Construire les variables
Pour illustrer la démarche on va développer un exemple : celui de la création de la variable Instances de gouvernances et implication des habitants.
Cette variable est issue de la combinaison d’informations qualitatives et quantitatives. Afin de pouvoir les travailler ensemble, il faut commencer par discrétiser la variable qualitative “nombre d’habitants associés aux instances de pilotage et de gouvernance” elle-même issue des variables SENACS :
- Instance(s) de gouvernance (nb d’habitants)
- Instance(s) de pilotage (nb d’habitants)
Cette démarche consiste, pour les variables de type quantitatif, à effectuer une discrétisation des données, c’est-à-dire la classification raisonnée des données. Elle doit conserver les caractéristiques essentielles présentées par les données afin de perdre le moins d’informations possible.
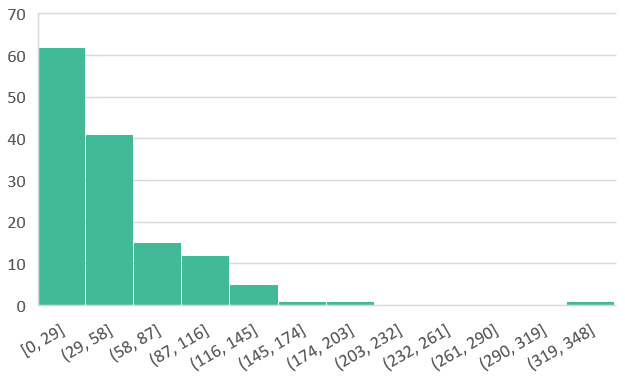
La discrétisation et catégorisation s’effectue grâce à un histogramme de fréquences (figure 1). Cette présentation montre la répartition des fréquences d’occurrence en paliers. On peut ainsi identifier les ruptures dans notre distribution pour créer des catégories pertinentes. Par exemple, pour la création de la variable nombre d’habitants associés à la gouvernance et au pilotage on constate deux ruptures dans notre distribution, la première à 29 et la seconde à 58. Après quoi on obtient trois catégories et donc 3 modalités catégorielles :
- NbHabAs- : moins de 29 habitants associés
- NbHabAs : entre 29 et 58 habitants associés
- NbHabAs + : plus de 58 habitants associés
Figure 1 : Histogramme de fréquence – nombre d’habitants associés à la gouvernance et au pilotage
Afin de combiner cette nouvelle variable à nos 2 autres variables qualitatives nous avons procédé à une reformulation des réponses aux questions portant sur le nombre d’instance de gouvernance ou de pilotage tel que :
- GouvNon : aucune instance associant les habitants à la gouvernance du centre
- GouvOui : au moins une instance associant les habitants à la gouvernance du centre
- PilNon : aucune instance associant les habitants au pilotage du centre
- PilOui : au moins une instance associant les habitants au pilotage du centre
Ensuite, nous avons construit un tableau de contingence des « profils lignes » (tableau 2), c’est-à-dire un tableau comptabilisant le nombre de ligne, soit des profils de centre, correspondant à la même combinaison de réponse.
Tableau 2 : tableau de contingence des profils lignes pour la gouvernance
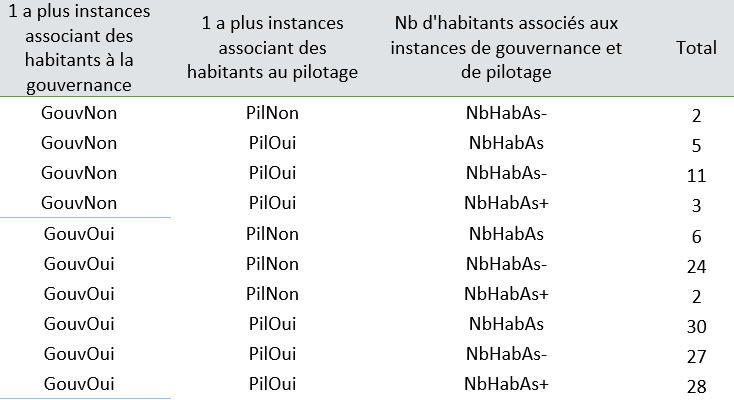
Cette démarche permet d’obtenir 5 modalités pour notre nouvelle variable :
- GP1 : aucune instance associant des habitants avec peu d’habitants participants
- GP2 : des instances associant des habitants à la gouvernance ou au pilotage avec une participation des habitants faible à moyenne
- GP3 : des instances associant des habitants à la gouvernance ou au pilotage avec une participation des habitants haute
- GP4 : des instances associant des habitants à la gouvernance et au pilotage avec une participation des habitants faible à moyenne
- GP5 : des instances associant des habitants à la gouvernance et au pilotage avec une participation des habitants haute
Comprendre les relations entre les variables
Avant de se lancer dans l’analyse multivariée, il est intéressant de se pencher sur les relations entre nos variables. C’est pourquoi, nous réalisons un test de corrélations (Khi²) afin de mesurer le degré d’indépendance des variables entre elles.
Le tableau 3 suivant présente les niveaux de signification des Khi² d’indépendance. Si le Khi² est inférieur à 5% (0,05) alors il y a rejet du test d’indépendance, autrement dit les variables sont dépendantes. En revanche si le test du Khi² est supérieur à 5% on déduit une relation d’indépendance entre les variables.
Tableau 3 : valeur de Khi² pour a comparaison de variables 2 à 2
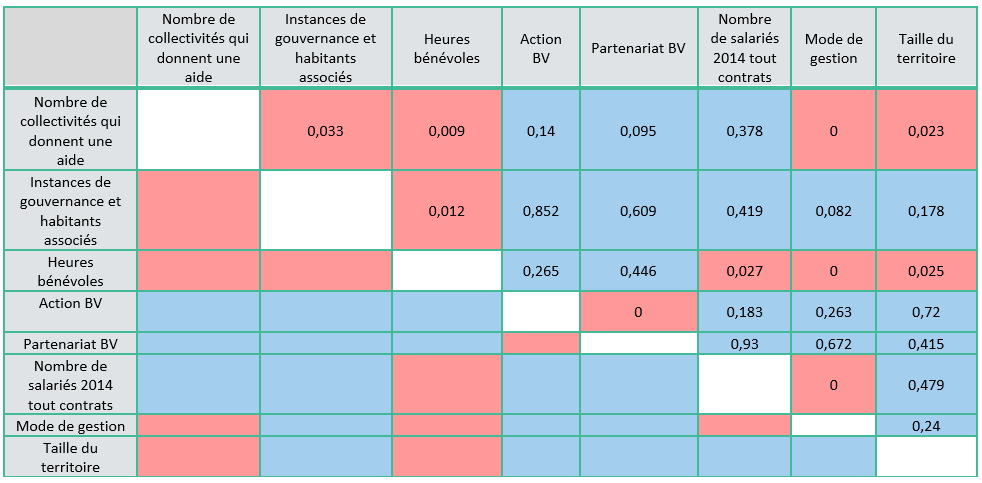
Analyser et interpréter le khi², permet d’ores et déjà de poser quelques hypothèses en comprenant quels sont les liens entres les variables. Par exemple :
La taille du territoire est corrélée avec le nombre de collectivités qui financent et avec les heures bénévoles.
- Nous pouvons faire l’hypothèse que plus le territoire d’intervention d’un centre social est grand plus les collectivités territoriales sont impliquées.
- La taille du territoire aurait également un lien avec les heures bénévoles, ainsi on peut émettre l’hypothèse que plus le territoire est grand plus le centre social génère d’heures bénévoles. (Soit par un nombre plus élevé de bénévoles soit par un temps de bénévolat plus important par personne).
Ce test permet également d’observer certaines redondances entre les variables. En effet, la valeur du Khi2 entre « partenariat bien vieillir » et « action bien vieillir » et entre « mode de gestion » et « nombre de salariés » est égal à 0. Ce résultat pose problème pour la suite de notre analyse, car des répartitions similaires de modalités au sein de ces variables peuvent déstabiliser l’ACM en « tirant » trop sur la construction de ses axes. C’est pourquoi, nous choisissons de les extraire de notre analyse.
Le test du Khi² est une première approche de ce qu’est capable de nous apporter le traitement de nos variables. Par conséquent, nous obtenons aussi de premières clés de compréhension sur les centres sociaux. Cependant le Khi² n’est pas suffisamment détaillé pour nous apporter des éléments de réponses sur nos individus, il est un indicateur des liens entre deux variables uniquement.
Analyse en correspondances multiples
L’intérêt de l’ACM, en plus de nous permettre de traiter nos données qualitatives et quantitatives, est d’obtenir à la sortie de l’analyse, une description synthétique des données qui préserve les proximités entre les individus, met en évidence les liaisons entre les variables et, éventuellement, permet de situer des groupes d’observations partageant les mêmes caractéristiques. L’ACM, permet de réaliser une présentation graphique type « nuage de points » de nos individus, les centres sociaux, en fonction de nouvelles coordonnées données sur des axes produits par l’ACM expliquant la répartition des individus suivant leurs modalités de réponses.
Ici, l’analyse nous donne 9 axes significatifs qui expliquent 62,22% de la répartition. Or, pour que les résultats restent pertinents nous devons limiter le nombre d’axes significatifs. On choisit de se limiter à trois axes, généralement le nombre d’axes conservés pour rendre significative une ACM.
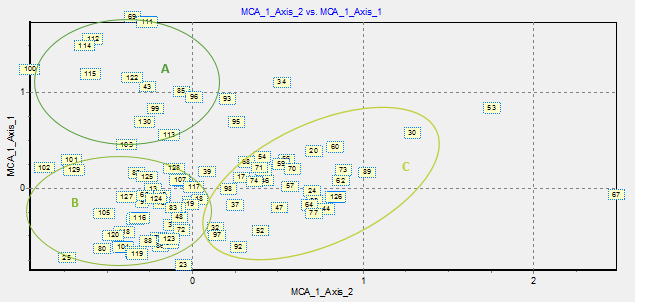
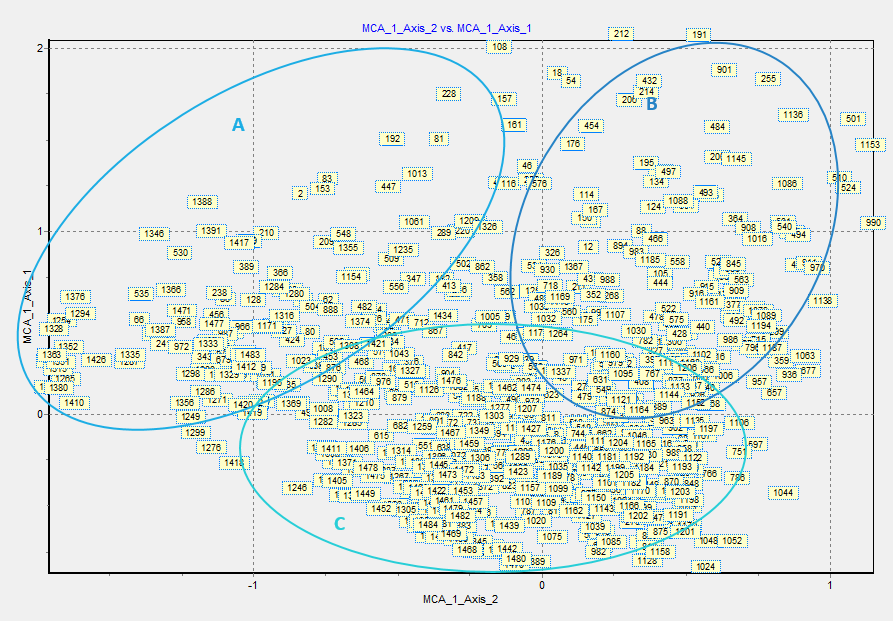
La figure 2 présente la distribution de notre population dans un référentiel sur un graphique présentant les deux premiers axes donnés par l’ACM axe 2/ Axe1. Une analyse rapide, nous permet d’identifier trois groupes :
- Groupe A : centre haut du graphique, autour de coordonnées 0 ; 1
- Groupe B : à gauche du graph en négatif sur l’axe 2
- Groupe C : à droite du graph en positif sur l’axe 2
Figure 2 : nuage de point de la répartition des CSX sur les axes 1 et 2
Afin de donner un sens à ces groupes, il nous faut donner un sens aux axes. Pour cela, nous analysons nos modalités. Comprendre la répartition de ces modalités sur les axes permet de saisir la direction que prennent les axes choisis.
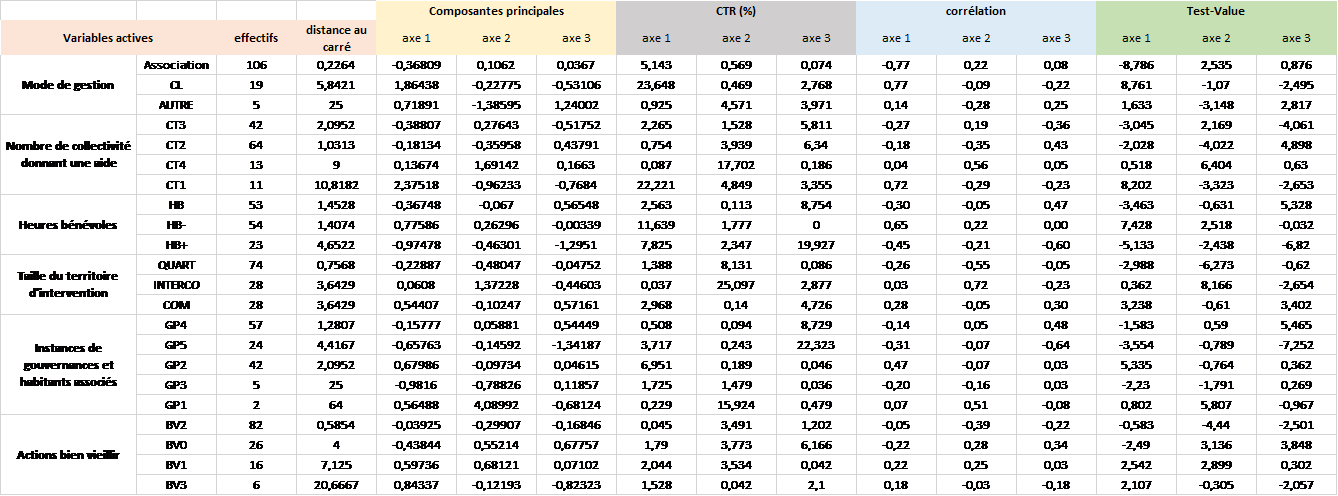
L’analyse des modalités se fait à l’aide du tableau 9. Celui-ci présente pour chaque modalité :
- Les effectifs
- Les distances carrées : soit la distance au khi2 qui est la distance entre les valeurs observées et les valeurs théoriques.
- Les composantes principales : qui sont les coordonnées de chaque modalité sur les nouveaux axes.
- La contribution : qui est la contribution de la modalité à la composante principale. (en %)
- Corrélation : qui est la racine du cosinus carrée des modalités. Un cosinus carré est la qualité de la représentation de la modalité sur l’axe principal.
- Valeurs-Tests : permet de déterminer si la modalité contribue de manière significative à un axe. On sait qu’une contribution est significative quand la valeur-test est supérieur à 2
Tableau 4 : analyse des modalités – CSX
Grâce à cet outil, il est possible d’identifier les modalités principales de chaque axe et leurs corrélations positives ou négatives.
On constate alors que l’axe 1 oppose CL et CT1 en corrélation positive (O.77 / 0.72) à HB+ et GP5 (-0.45 / -0.31) en corrélation négatives. En d’autres termes il y a opposition entre des centres en gestion de collectivités locales financés par une collectivité territoriale d’un côté et des centres à fort bénévolat et participation des habitants de l’autre.
L’axe 2 oppose INTERCO (0.72) et CT4 (0.56) en positif à BV2 (-0.39) et Quartier en négatif (-0.55). Autrement dit il oppose des centres à territoire d’intercommunaux avec de nombreuse CT aidantes à des centres de quartier avec 2 à 5 types d’actions Bien vieillir.
L’axe 3 quant à lui oppose HB et GP4 (0.47/0.48) en corrélations positives GP5 et HB+ (-0.64/-0.60) en corrélations négatives soit des centres avec des heures bénévoles et une participation moyennes à des centres avec un bénévolat et une participation importante.
Si l’on observe à nouveau nos groupes, on constate maintenant que le groupe A avec des coordonnées positives en axe 1 serait principalement composé de centres gérés par des collectivités locales. De même, la distinction entre les groupes B et C, l’un positif et l’autre négatif sur l’axe 2, peut s’interpréter comme une distinction de territoires d’intervention. Ainsi le groupe B regrouperait les centres de Quartier et le groupe C les centres intercommunaux.
Néanmoins cette interprétation se base sur une représentation sur deux axes or nous avons trois axes significatifs, c’est pourquoi une représentation en 3 dimensions conviendrait davantage. Cependant cela est plus délicat à produire et à lire. De plus, en ne retenant que les corrélations les plus fortes de nos axes dans nos interprétations on perd en précision. C’est ici et pour cette raison que la Classification ascendante hiérarchique (CAH) intervient.
La Classification ascendante Hiérarchique
La CAH est une méthode de classification en association successives des individus par degré de similitude croissant. C’est-à-dire que l’on part de l’ensemble de la population et on créé des regroupements 2 par 2 successives pour arriver à chaque individus. Ceci se présente sous la forme d’un Dendrogramme (fig.3).
Figure 3: dendrogramme de CAH
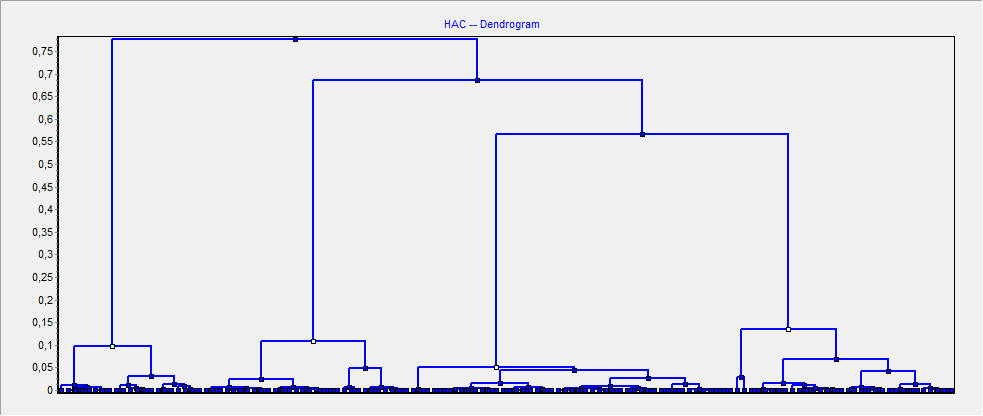
Il s’agit ensuite de choisir un niveau de partition coupant le Dendrogramme à un seuil donné pour obtenir nos classes. Ici, notre seuil de partition nous est donné directement par le logiciel dans une répartition « Best cluster sélection ». On obtient au final, 4 classes,
- Groupe A : 20 individus
- Groupe B : 31 individus
- Groupe C : 49 individus
- Groupe D : 30 individus
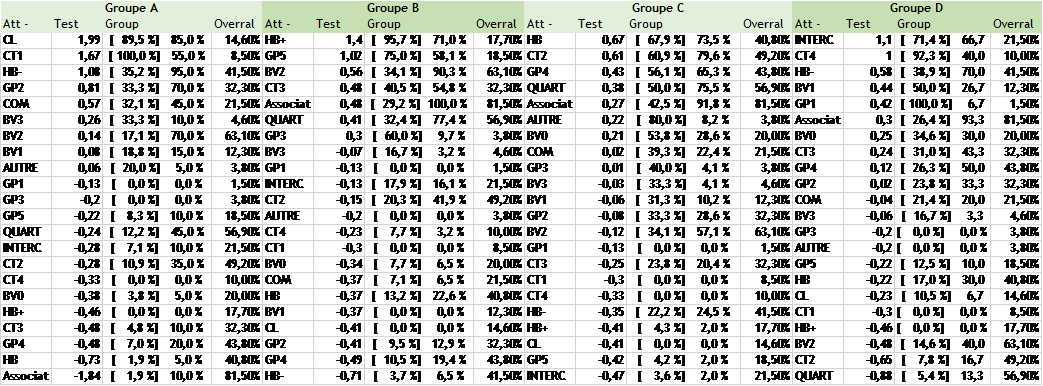
Les caractéristiques de chacun des groupes sont données dans le tableau 10. Ce tableau permet de voir le poids de chacune des modalités dans la constitution de chaque groupe. Ce sont les valeurs-tests qui permettent de l’illustrer. Par exemple, pour le groupe A la modalité la plus importante dans la construction du groupe est la modalité CL (1,99). Les colonnes « GROUP » nous donne le pourcentage des individus qui ont répondu à la modalité et qui apparaissent dans ce groupe. 85% des individus qui ont répondu « CL » sont dans le groupe A.
Ainsi, la CAH trouve toute son importance. En effet, même si les interprétations des groupes précédant nous permettaient de supposer l’importance du mode de gestion dans la classification des centres, nous pouvons maintenant et le confirmer et le nuancer. Bien que la variable « mode de gestion » figure toujours dans les 5 premières valeurs-tests de chaque groupe, elle n’est principale que pour le groupe 1.
Tous ces facteurs nous permettent de formuler les constats suivants :
- Groupe « A » : des centres en gestion par collectivités locales sur des territoires communaux, se situant dans la moyenne supérieure en termes d’action « bien vieillir » avec un faible bénévolat
- Groupe « B » : globalement composé de centres sociaux associatifs à l’échelle du quartier, dont la participation et l’association des habitants à la gouvernance est moyenne à élever. Le bénévolat y est important, ceux-ci se situent dans la moyenne supérieure en termes d’action « bien vieillir ».
- Groupe « C » : à plus ou moins les mêmes caractéristiques que le groupe B. Cependant le bénévolat est moyen plutôt qu’élevé et les centres ne se caractérisent pas en termes d’action bien vieillir.
- Groupe « D » : des centres à territoire intercommunal financés par plusieurs collectivités territoriales avec une somme d’heures de bénévolat basse.
Tableau 5 : répartition des modalités par groupe de la CAH
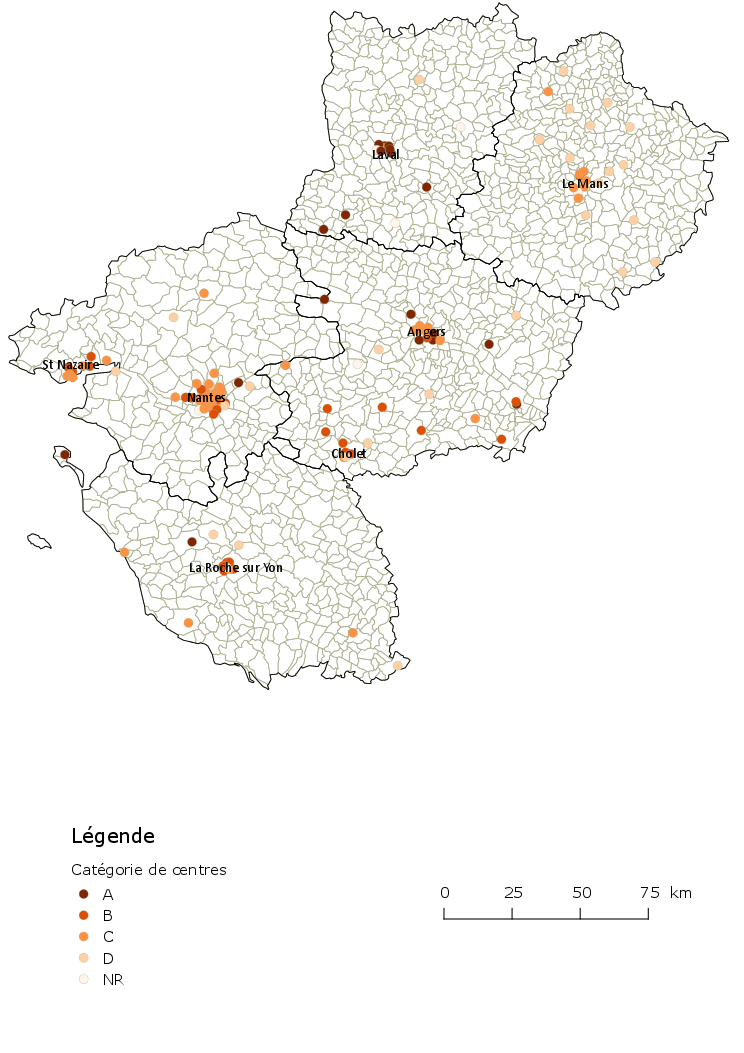
Il est intéressant de regarder la distribution spatiale des catégories (fig.8). On remarque alors que la catégorie 2 est dominante dans les préfectures à l’exception le Laval. De plus, il y a des spécificités départementales :
- Il n’y a pas de catégorie A en Sarthe et peu en Loire atlantique mais une prédominance en Mayenne
- Il n’y a pas de catégorie B en Mayenne et en Sarthe
- Il y a seulement un centre en catégorie A en Loire-Atlantique
- La catégories C est dominantes en Loire Atlantique
- Le Maine et Loire et la Vendée semble présenter une distribution équilibrée entre les 4 catégories.
Figure 4 : Carte des CSX en Pays de la Loire selon leurs catégories
Construction des variables de territoires
Il est nécessaire de réaliser une typologie de territoire afin de pouvoir compléter la typologie des centres sociaux. En effet cela devrait nous permettre de choisir, pour la construction de notre panel final, les centres sociaux à partir de leurs critères et de leurs territoires d’implantation. Afin de réaliser cette typologie nous avons besoin de constituer une base de données présentant des indicateurs sur les différents aspects du territoire.
Pour les besoins de l’étude nous choisissons de sélectionner des indicateurs tant sur les communes que sur leur population elles-mêmes :
- Un indice démographique: l’étude portant sur le « bien vieillir », il semble crucial de garder une dimension démographique. C’est pourquoi on a choisi l’indice qui exprime le taux de la population âgée (plus de 60ans) par rapport à la population jeune (moins de 20ans). Utiliser cet indice permet de supprimer les écarts de valeurs brutes de populations dus à la taille des communes. Pour calculer les indices de vieillissement, on se base sur les résultats du recensement général de la population de 2012 (INSEE 2012) en calculant le rapport entre la population de plus de 60 ans et celle de moins de 20 ans. On obtient alors une valeur autour de 100 (sauf cas aberrent). Plus la valeur est faible, plus le rapport penche en la faveur des jeunes
- Une indication socioprofessionnelle: cela permet de caractériser la population et d’en déduire des informations sur le niveau de vie et les classes sociales. Comme pour des raisons de pertinence et de lisibilité des résultats nous ne pouvons pas conserver la totalité des classes socioprofessionnelles, nous choisissons de n’en garder que 2. On conserve Ouvriers et Cadres et professions intellectuelles supérieures qui caractérisent deux classes socioprofessionnelles bien distinctes.
- Une indication en termes de « niveau de diplôme »: qui permet de faire le lien avec les CSP présentent sur le territoire et qui est un indice de classe sociale. Comme précédemment on ne conserve que les extrêmes, ici sans diplôme et diplôme universitaire que l’on exprime en pourcentage
- Une indication sur le niveau d’équipement: qui illustre une certaine fracture, une inégalité territoriale entre des communes bénéficiant de tous les équipements et d’autres, généralement isolées où les services sont absents. On garde ici deux variables : l’indication sur les services publics tel que définie dans la base permanente d’équipements (INSEE) et la présence d’établissements hospitaliers issus des répertoires FINESS
- Une information sur le type de territoire: il semble évident que le ‘type’ de commune, c’est-à-dire son inscription dans un milieux urbain ou rural, est un facteur important à prendre en compte
Chacune de ces informations sont ensuite discrétisées afin d’avoir nos catégories pour faire notre ACM (cf.tab.6).
Tableau 6 : descriptif des variables de territoires
ACM et CAH sur les communes des Pays de la Loire
Après avoir détaillé chacune des étapes de l’interprétation de l’ACM pour l’analyse des centres sociaux nous allons passer directement aux résultats de l’analyse.
L’interprétation de l’analyse des modalités de notre ACM nous permet de formuler les caractéristiques suivantes pour les 3 axes principaux. Ainsi :
- L’axe 1 oppose DUniv ++ et Prof ++ en corrélation positive à Prof- et Rural en corrélation négative.
- L’axe 2 quant à lui oppose ServHosp0 et ServPub0 en positif à ServHosp2 et AucDip+ en négatif.
- Enfin l’axe 3 oppose EQU et AucDip+ en positif et AucDip- et Prof + en négatif.
Figure 5 : nuage de point de répartition des communes sur les axes 1 & 2
En se reportant à des groupes pressentis sur le nuage de point (fig.5) on peut formuler les hypothèses suivantes quant à leurs caractéristiques.
- Le groupe A avec des coordonnées positives sur l’axe 1 présenterait des territoires avec une population importante ayant un diplôme universitaire et exerçant des professions intellectuelles supérieures. Tout en étant via ses coordonnées négatives sur l’axe 2 composé de territoires bien desservis en termes de services hospitaliers et qui présentent peu de personnes sans diplômes. Ces caractéristiques nous permettent de supposer que les communes du groupe 1 seraient principalement des communes urbaines à métropolitaines.
- Le groupe B aurait les mêmes caractéristiques que le groupe 1, en ce qui concerne les diplômes universitaires et les professions intellectuelles supérieures puisqu’il est également en positif sur l’axe 1. Mais ses territoires disposeraient de peu de services publics ou hospitaliers. Ceux-ci ont des caractéristiques semblables aux communes de type ville isolée avec beaucoup de « navetteurs ».
- Enfin, le groupe C avec des coordonnées négatives sur l’axe 1 regrouperait des communes de milieu rural avec peu de professions intellectuelles supérieures.
Cette classification permet d’identifier de grandes orientations de classement, néanmoins se baser uniquement sur le type (rural/urbain) est trop minimaliste pour illustrer la diversité des territoires que l’on a pourtant souhaité conserver dans l’analyse.
C’est pourquoi nous approfondissons nos données à l’aide d’une CAH. Le logiciel effectue une détection en « Best-Clusturing » à 4 catégories.
- Groupe 1 : 240 communes soit 16,8%
- Groupe 2 : 326 communes soit 22%.
- Groupe 3 : 643 communes soit 43,3%
- Groupe 4 : 265 communes soit 17,9%.
L’interprétation du tableau de répartition des modalités nous permet de caractériser nos groupes tel que (fig 6):
- Les caractéristiques principales du groupe 1 : Ce groupe semble, rassembler des territoires de milieux urbains bien équipés en services. Par conséquent, on en déduit que cette catégorie regroupe les grands centres urbains et les villes secondaires, isolées.
- Les caractéristiques principales du groupe 2 : On est ici en présence de communes avec une forte population vieillissante et peu diplômée. Dans ce cas, on suppose des territoires ruraux vieillissants.
- Les caractéristiques principales du groupe 3 : Ce groupe se composerait de territoires ruraux plutôt jeunes avec peu de services soit des territoires agricoles.
- Enfin, le groupe 4, se caractérise par : des communes qui semblent être « périurbaine dynamique » ce qui correspondrait aux bordures des grands centres urbains. (Logement des classes supérieures et travail en ville).
Figure 6 :
Afin de comprendre quels territoires appellent quels types de centres sociaux on attribue à chaque centre social le numéro de la catégorie à laquelle appartient sa commune.
Cependant, on constate une surreprésentation de la catégorie 1. En effet, la distribution des catégories de territoires sur les CSX nous donne la répartition suivante :
- Catégorie 1 : 102/140 centres.
- Catégorie 2 : 3/140 centres
- Catégorie 3 : 4/140 centres
- Catégorie 4 : 31/140 centres
Cette répartition nous apprend que les territoires de centres sont principalement des territoires urbains. Bien que ce soit une conclusion importante il est nécessaire d’obtenir un panel plus varié, c’est pourquoi nous procédons à une nouvelle analyse en ne prenant en compte que les communes où il y a la présence d’un centre social.
ACM & CAH pour les communes de CSX
On reprend donc notre tableau de base des communes mais on ne conserve que les communes dotées d’un centre social. On obtient au final 74 communes. De plus, on remarque que l’on perd deux modalités : ServHosp0 et Ouv ++.
L’analyse des modalités effectuée à partir du tableau 15 nous permet d’identifier les oppositions d’axes suivantes :
- axe 1, opposant Prof- et AucDip ++ à Prof ++ à DUniv ++.
- axe 2 opposant AucDip ++ et Prof- à DUniv + et Prof-.
- axe 3 opposant ServHosp1 et ServPub0 à AucDip+ et ServPub2
On fait donc la CAH qui nous propose 4 catégories de territoire.
- Catégorie 1 : avec 20 territoires soit 27%.
- Catégorie 2 : 6 soit 8,1%
- Catégorie 3 : 25 pour 33,8%
- Catégorie 4 : 23 pour 31,1%.
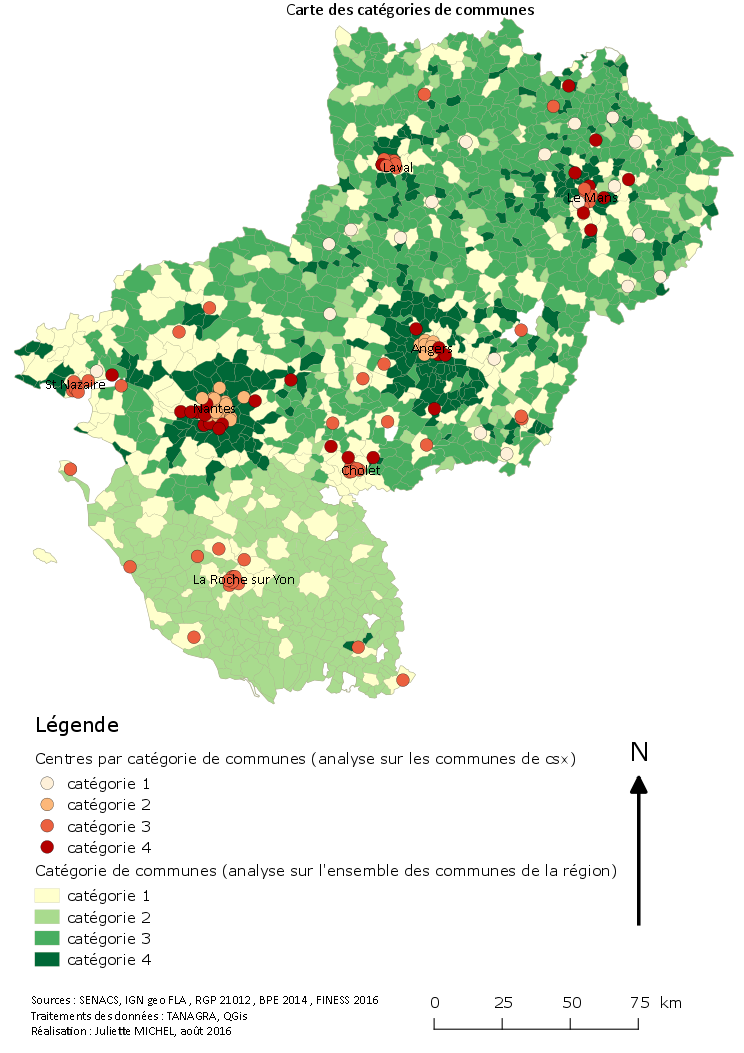
L’étude du tableau de la répartition de modalité par catégorie montre que l’on retrouve dans la catégorie 1 des territoires ruraux, jeunes et ouvriers. On suppose du rural agricole et/ou des territoires avec une dominante socioprofessionnelle dans la tranche inférieure. Pour la catégorie 2 on constate des professions intellectuelles supérieures aux diplômes élevés avec une population jeune. Soit des territoires urbains voir métropolitains. La catégorie 3 regroupe des villes isolées, bien équipées en termes de services publics mais principalement composées d’une population âgée. On suppose des villes secondaires et/ou avec une forte population de retraités. La catégorie 4 montre peu de non diplômés mais beaucoup de professions intellectuelles supérieures en banlieue. Des territoires avec peu de services publics et hospitaliers. On suppose des territoires de couronnes urbaines et des classes moyennes.
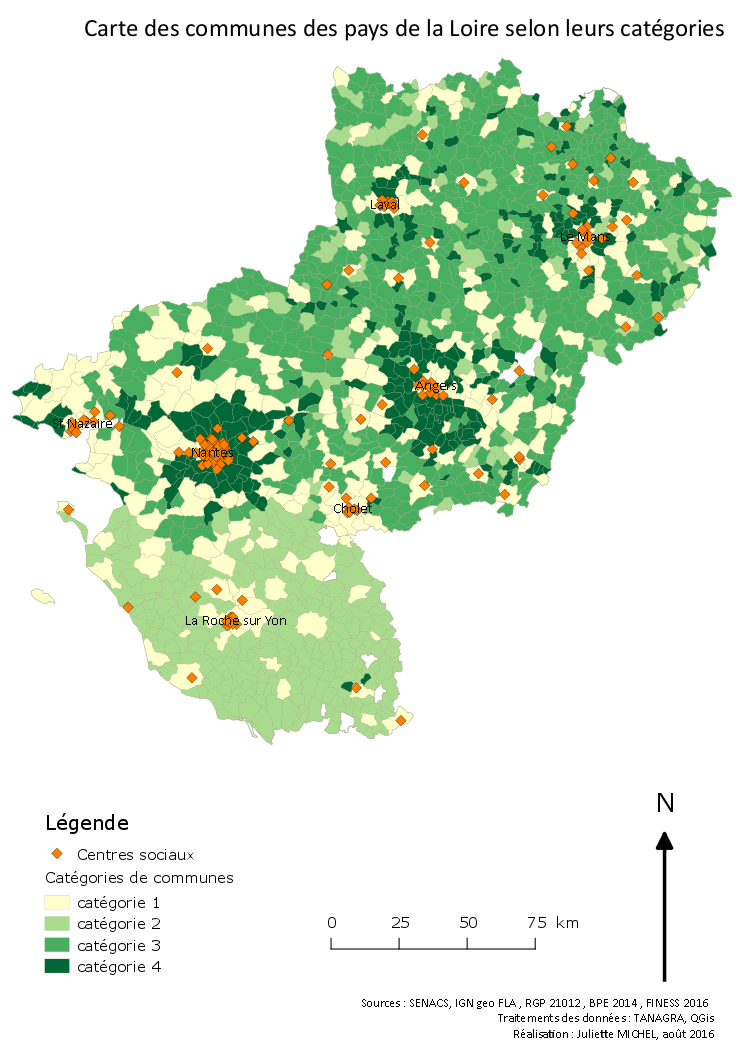
La lecture de la carte en figure 7 nous permet de confirmer ces hypothèses.
- Les catégories 1 sont situées dans des espaces ruraux ou de campagne.
- Les catégories 2 sont concentrées sur les deux espaces métropolitains de Nantes et Angers.
- Les catégories 3 se retrouvent sur le maillage urbain et les espaces « vieillissants » en Vendée.
- Les catégories 4 se retrouvent dans les couronnes urbaines Nantes et Angers.
Figure 7 :
Conclusion
La typologie ainsi faite, nous pouvons désormais choisir les centres sociaux qui feront l’objet de notre enquête. Pour des raisons de représentativité et de moyens, la recherche ne peut explorer l’ensemble des centres sociaux de la région. En révélant des catégories, en effectuant des regroupements selon des critères préalablement choisis, celle-ci nous offre une grille de lecture sur l’ensemble des centres sociaux du territoire des pays de la Loire. Nous permettant maintenant d’établir un choix raisonné et représentatif sur les structures qui seront étudiées.
Afin de réaliser la sélection de notre échantillon, la prochaine étape consistera à étudier les résultats de la typologie afin d’avoir dans notre panel des individus appartement à des groupes différents. Nous veillerons également à ce que tous les départements de la région soient représentés. C’est ici que les deux typologies croisées vont être utiles. Lorsque plusieurs structures apparaîtront dans une même catégorie dans la typologie des centres sociaux nous les comparerons avec les groupes dans lesquels elles apparaissent dans la typologie territoire. Si elles montrent des regroupements similaires nous les trierons en fonction des autres critères à prendre en compte (département, gestion, territoire d’action) et les comparerons à celles déjà retenues. Dans le cas où elles sont seules, elles seront automatiquement retenues. De cette façon nous obtiendrons un échantillon varié et représentatif des différents cas de figures qui existent en termes de structure centre social sur le territoire des Pays de la Loire.
Nous rappelons que dans le mesure du possible, cette démarche, a pour objectif d’être applicable à l’ensemble du territoire Français.
Références
Blin, Eric, et Jean-Paul Bord. 1993. Initiation Géo-graphique ou comment visualiser son information. 2eéd. Sedes.
« Charte des centres sociaux et socioculturels de France ». 2010. http://www.centres-sociaux.fr/files/2010/02/Charte-des-centres-sociaux-et-socioculturels-de-France.pdf.
FINESS. 2016. « Consulter la base : Recherche par thème ». http://finess.sante.gouv.fr/jsp/rechercheSimple.jsp?coche=ok.
INSEE. 2012. « Recensement général de la population ». http://www.insee.fr/fr/themes/detail.asp?reg_id=99&ref_id=base-cc-evol-struct-pop-2013.
———. 2015. « Base permanente des équipements ». http://www.insee.fr/fr/themes/detail.asp?ref_id=fd-bpe15&page=fichiers_detail/bpe15/telechargement.htm.
———. 2016. « Définitions, méthodes et qualité – Aire urbaine ». Consulté le août 12. http://www.insee.fr/fr/methodes/default.asp?page=definitions/aire-urbaine.htm.
Ricco Rakotomalala. 2005. « TANAGRA : un logiciel gratuit pour l’enseignement et la recherche ». Actes de EGC 2: 697‑702.
SENACS. 2016. « Liste des Centres sociaux ». http://www.senacs.fr/structure/csx.
Tenenhaus, Michel. 1996. Méthodes Statistiques en Gestion. Dunod.
Shani GALAND
Chargée de mission Union Régionale des centres sociaux et socioculturels des Pays de la Loire – Doctorante en Sociologie laboratoire CENS
Juliette MICHEL
Chargée de mission Union Régionale des centres sociaux et socioculturels des Pays de la Loire – Doctorante en Géographie laboratoire ESO
Traitement des données fait avec les logiciels : TANAGRA, Excel & QGis